
WHAT IS CRAWL BUDGET?
Crawl budget is the number of pages search engines must crawl on a website within a certain time line. A web crawler, spider, or search engine bot can download and index content from all over the internet. The goal of this bot is to learn what each and every webpage on the internet is about, so that the information can be restored when it is needed. It is called web crawlers because it’s crawling over other websites.

CAN CRAWL BUDGET AFFECTS SEO?
Crawl budget is not working to rank for technical SEO. If Google Bot experiences crawl errors that prevent it from reading and indexing your content, the chances of your pages showing up on search engine results pages are slim. Exceeding the allocated budget for crawling the website can lead to slowdowns or errors in your system. Therefore, it can lead to pages being indexed late or resulting in lower search results. Google takes hundreds of signals to decide whether they should be placed on your page or not. Crawling helps your page show up, and it has nothing to do with quality content.
HOW DOES GOOGLE DETERMINE THE CRAWL BUDGET / WHAT TRICKS GOOGLE WANTS TO KNOW
Each and every website has a unique crawl budget managed by two main elements: crawl demand and crawl limit. It’s important to understand how they work.
CRAWL DEMAND
Crawl demand refers to how much desire Google has to crawl your website. Popularity and staleness these two factors affect crawl demand.
Popularity
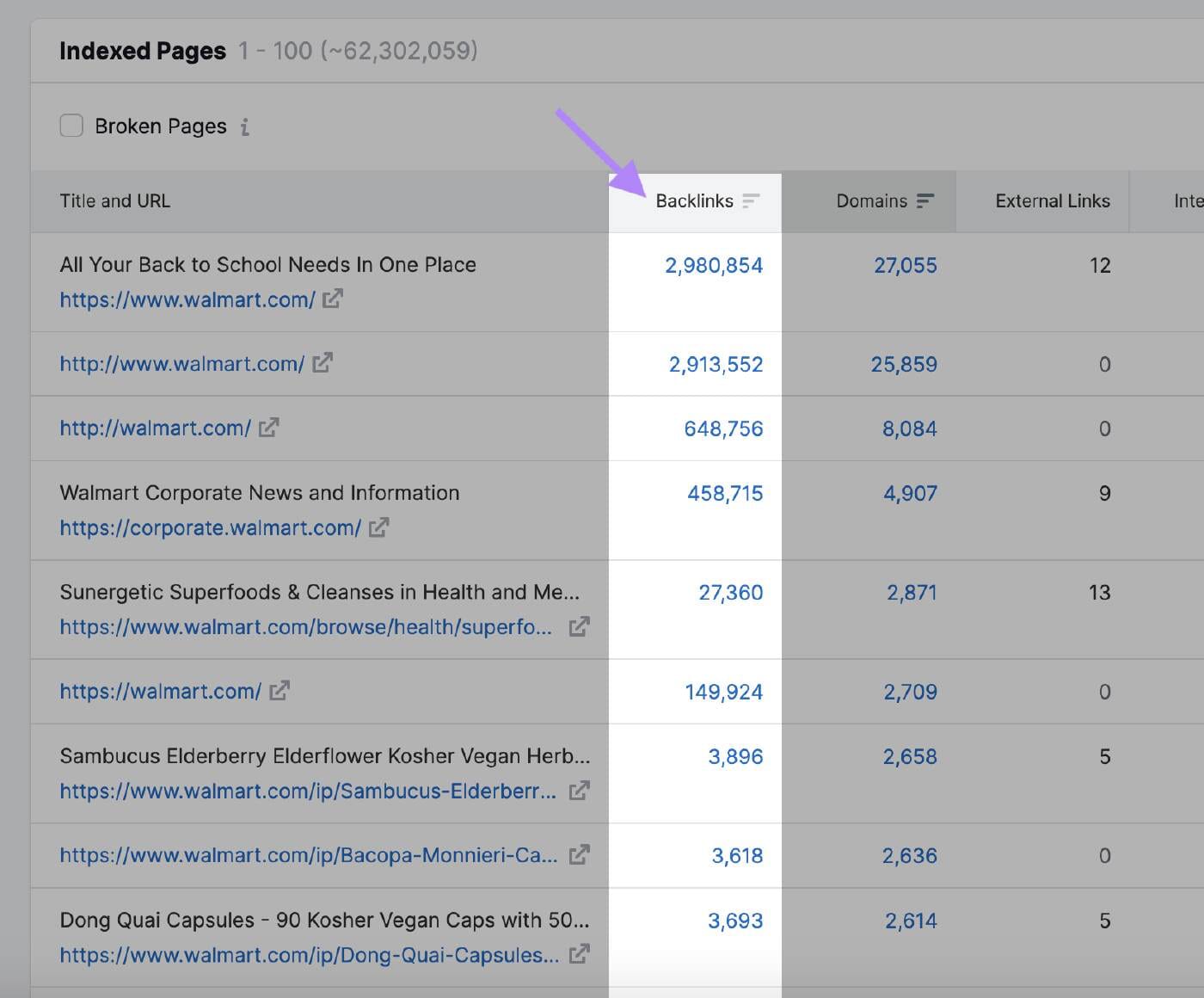
Google always prioritizes pages with more backlinks or those that attract more traffic. After that, if people are visiting your website, the Google algorithm brings signals that your website is valuable for more frequent crawls. Backlinks are especially useful for Google to figure out which pages are worth crawling. If Google notices people are talking about your website, it wants to crawl your website more. You can see the performance with pages of the most backlinks.
Staleness
Google may not crawl a page that has not been updated frequently. Google has not revealed the frequency level at which the search engine really wants to crawl your website. If the Google algorithm notices a general site update, Google temporarily increases the crawl budget. For example, Google basically crawls news websites frequently because these websites regularly publish new content several times a day. This type of website has high crawl demand. On the other side, those websites that have a lower frequency of update can follow other processes as follows:
Domain name change – If you change your website’s domain name, it can affect Google’s algorithm and update a new index to reflect the new URL. It will crawl your website to understand the change and can pass the ranking signals to your new website.
URL structure change – Modifying URL structure can be a game changer for your website. Google’s bot will recrawl the pages of your website to index the new URLs accurately.
Content updates – Adding new pages or updating your content on your website and removing the outdated content can attract the algorithm’s attention and prompt it to recrawl your pages as well as your website.
XML sitemap submission – Updating your XML site map and resubmitting it to Google is most helpful for your website’s crawling.
CRAWL RATE LIMIT
The crawl rate limit depends on how fast the bot can access and download web pages from your site to manage the content for serving on search results. The crawl limit prevents the bot from bogging down your website with too many requests, which can raise performance issues.
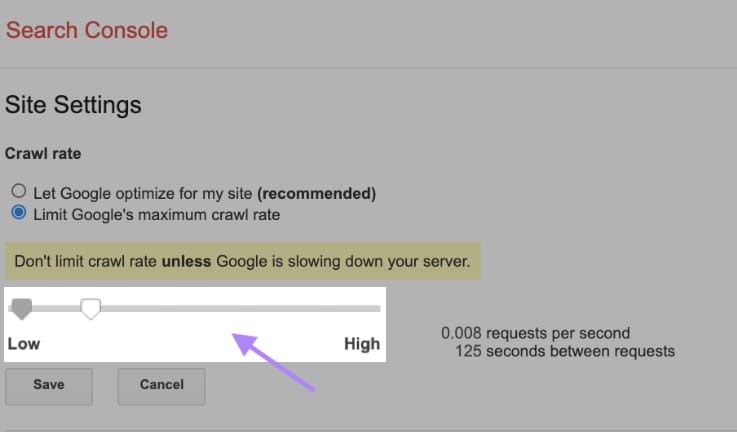
If your site answers quickly, Google gives the green light to increase the limit, and it can then use more resources to crawl it. Similarly. If Google faces server issues or your site slows down, the limit will fall and Googlebot will show less crawl.
Although you can change the crawl limit manually, there is a caution. You can do it only when Google suggests not to limit the crawl rate unless your server faces issues. You can change the crawl rate setting by going to the site setting on the search console. This typically takes up to two days to show on your site.
HOW DOES THE CRAWLING PROCESS WORK?
The crawling process takes bots to discover, crawl, analyze, and index web pages to provide users with the most relevant and quality search results.
The internet is constantly changing and expanding gradually. Because it is impossible to know how many total web pages there areon the internet, web crawler bots start from seed, or a list of known URLs. Then Google accesses web crawlers to visit these websites, read the information, and follow links on those pages.
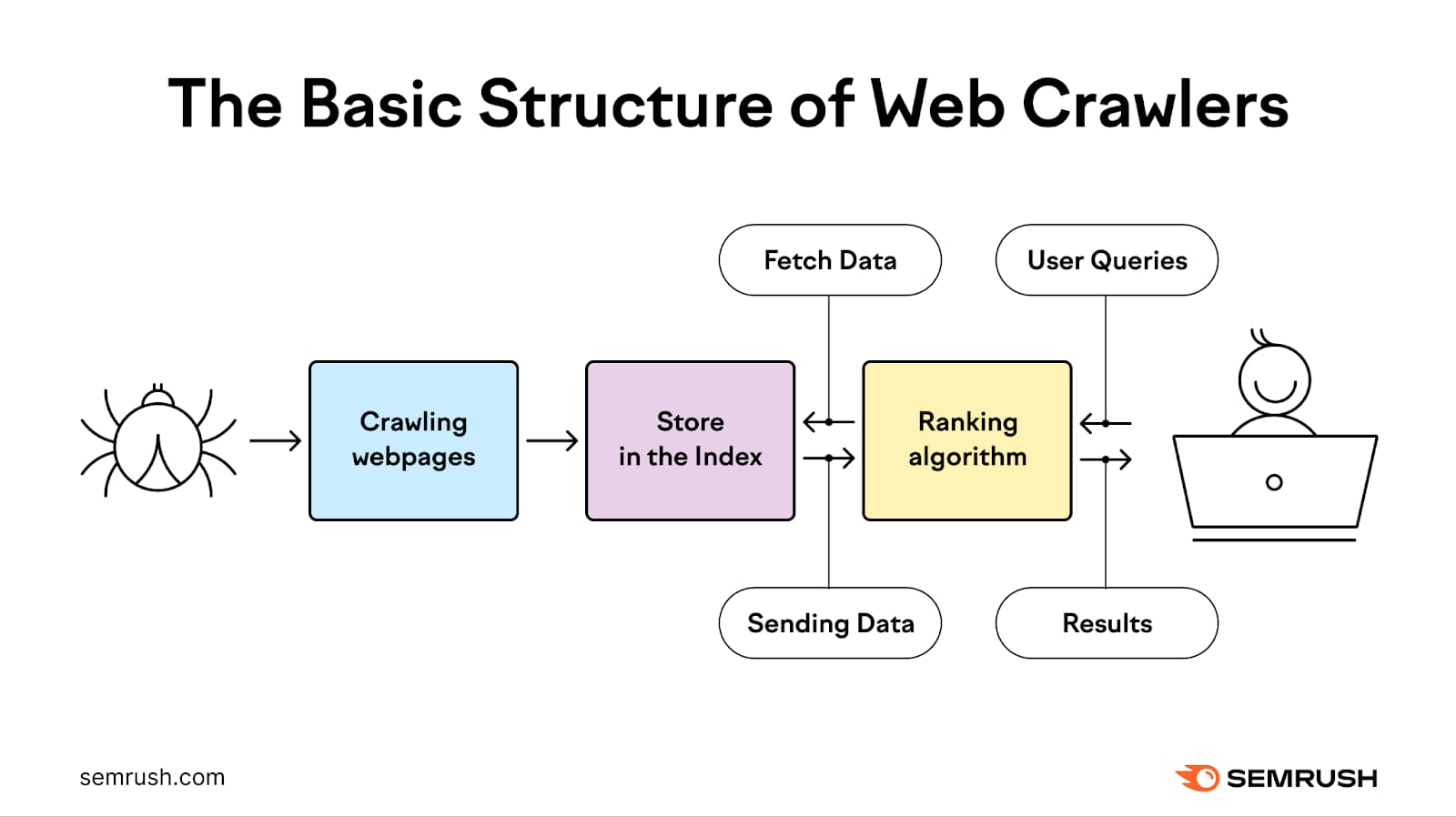
Basically Google crawls smaller websites efficiently most of the time. When it comes to a big website with lots of URLs, Google only prioritizes what ,when, and how many resources it should be dedicated to.
HOW TO CHECK YOUR CRAWL ACTIVITY
Google Search Console shares complete information on your crawl activity, like crawl errors and crawl rate. A crawl status report may help you double check whether Google can access and index your content properly. It can help you to find any issues and solve it before your website’s visibility falls.
The summary page gives you a lot of information. The main points are:
Over time chart- This chart provides your crawl data for the past 90 days.
Grouped crawl data- Grouped crawl data shares information on crawl requests.
Host status- This status shows your site’s general availability, and Google can access it without any problems on the other side. There are lots of factors involved.
ADJUST CRAWLER SETTINGS
It will help you to choose the kind of bot crawl your site. You have to choose between Googlebot and Semrush and mobile and desktop versions. Then select your crawl delay settings. Bot crawl at a normal speed with “minimum delay” and give importance to the user experience in the ‘1 url per 2 seconds’ settings. Finally, select “respect robot.txt” if you have a similar file and need a specific crawl delay .YOUTUBE LINK
Allow / disallow URLs
Allow/disallow URLsettings customize your site audit by entering the URLs in their corresponding boxes.
Remove URL parameters
Ignoring URL parameters ensures the bots don’t waste the crawl budget by crawling the same page twice.
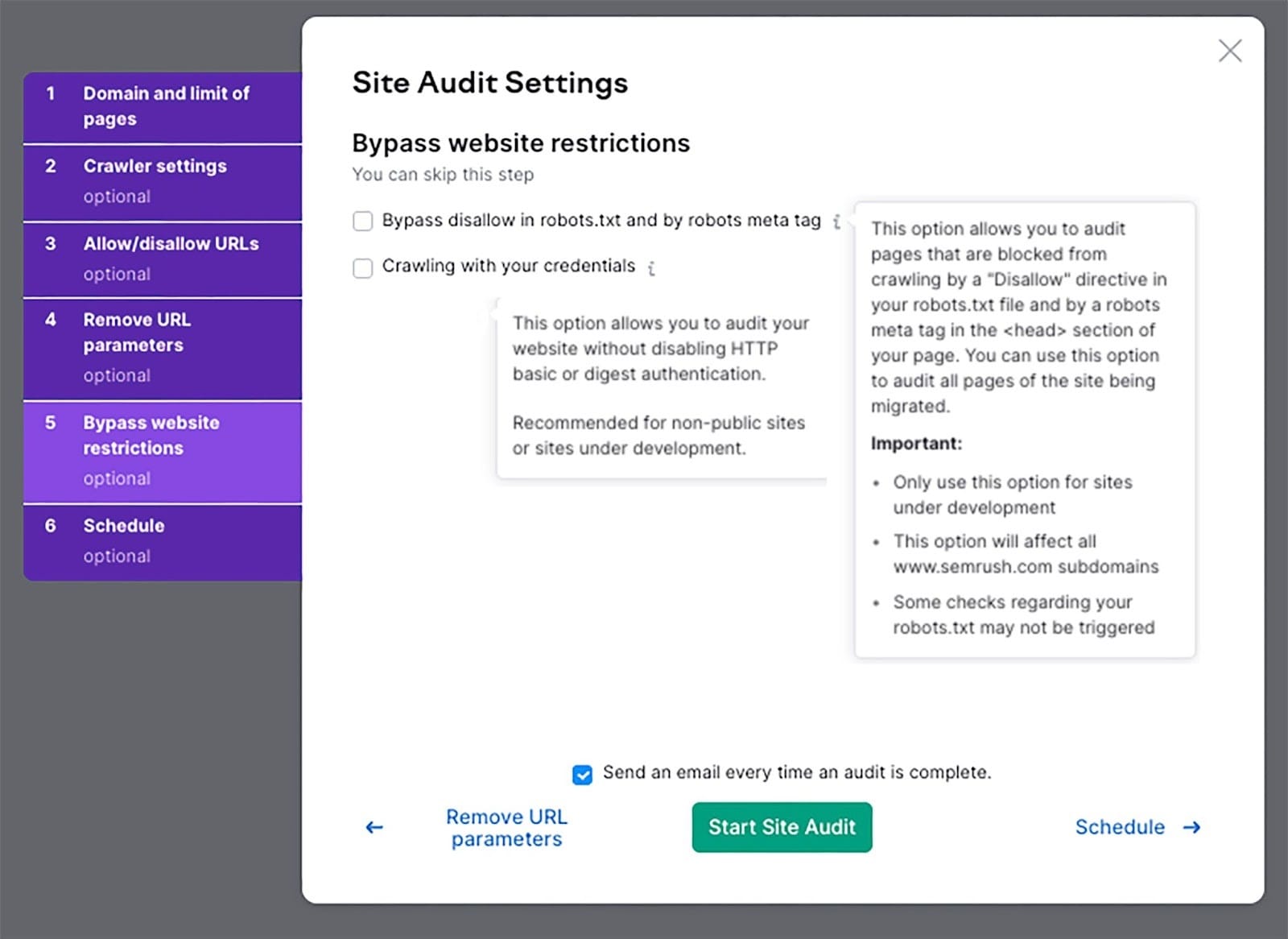
Bypass website restrictions
If your website is still under maintenance, use this setting to run an audit.
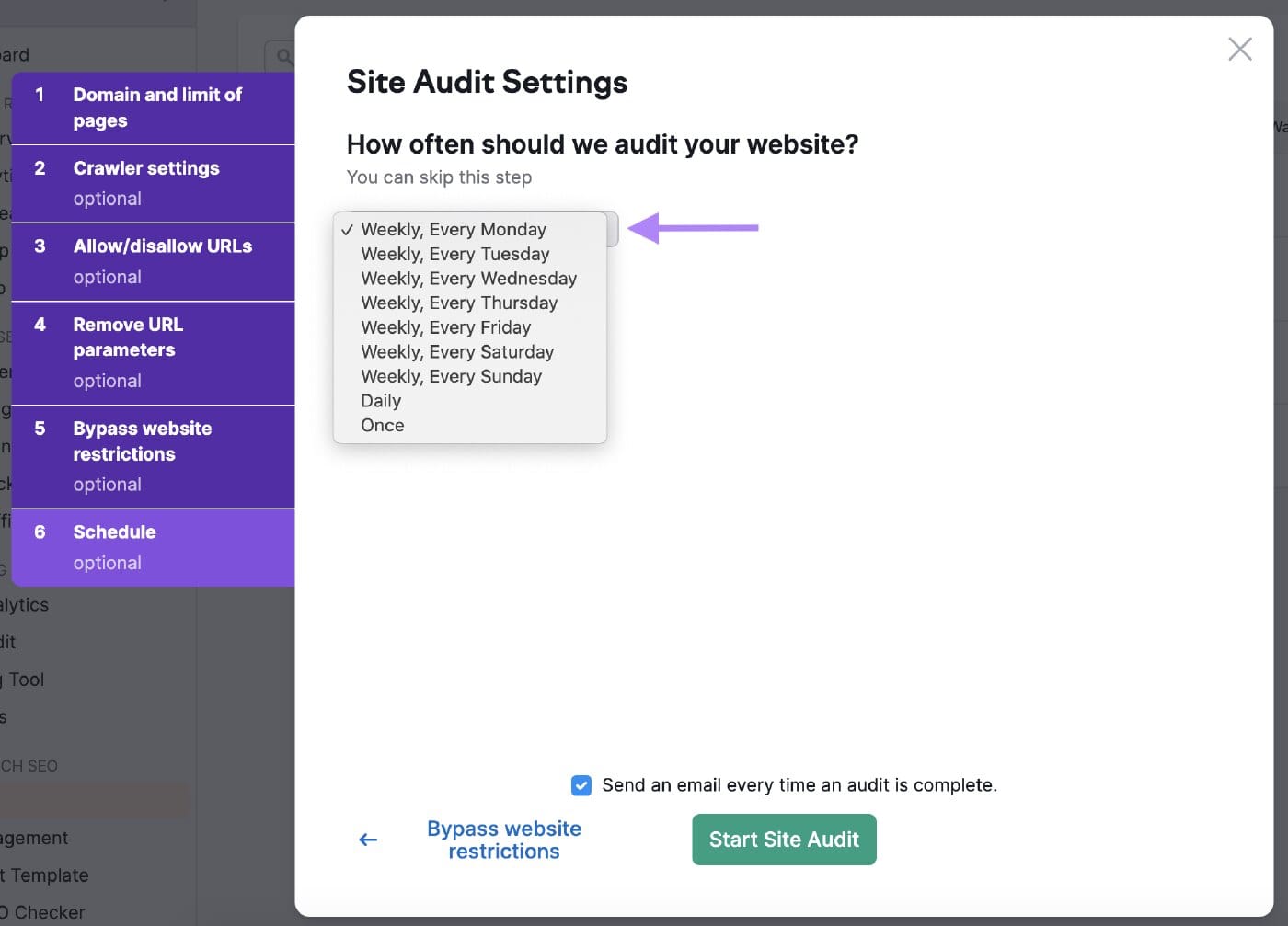
Schedule your audits
You can schedule audits of your website based on how often you want the bot to audit your site. Scheduling it frequently can ensure the tool checks your website’s health regularly.
WHY ARE WEB CRAWLERS CALLED SPIDERS?
The internet, the part that most users can access, is also known as the world wide web (www), therefore, that’s where the “www” part of most website URLs comes from. It is naturally called the search engine bots “spiders” because they crawl all over the web, just as a real spider crawls over spiderwebs.
LIST OF WEB CRAWLERS
The bots from major search engines are called as follows:
GOOGLE : Googlebot has two crawlers, Google Bot desktop, and Googlebot mobile for desktop and mobile users.
Bing: Bingbot.
DuckDuckGo: DuckDuckBot.
Yahoo! Search:Slurp.
Yandex: YandexBot.
Baidu: Baiduspider.
Exalead: Exabot.
There are many other web crawler bots available but not associated with any search engines.
